Architecture overview
Seafowl consists of several components. It ships with self-contained defaults, but supports advanced deployment patterns through swapping out some of the components.
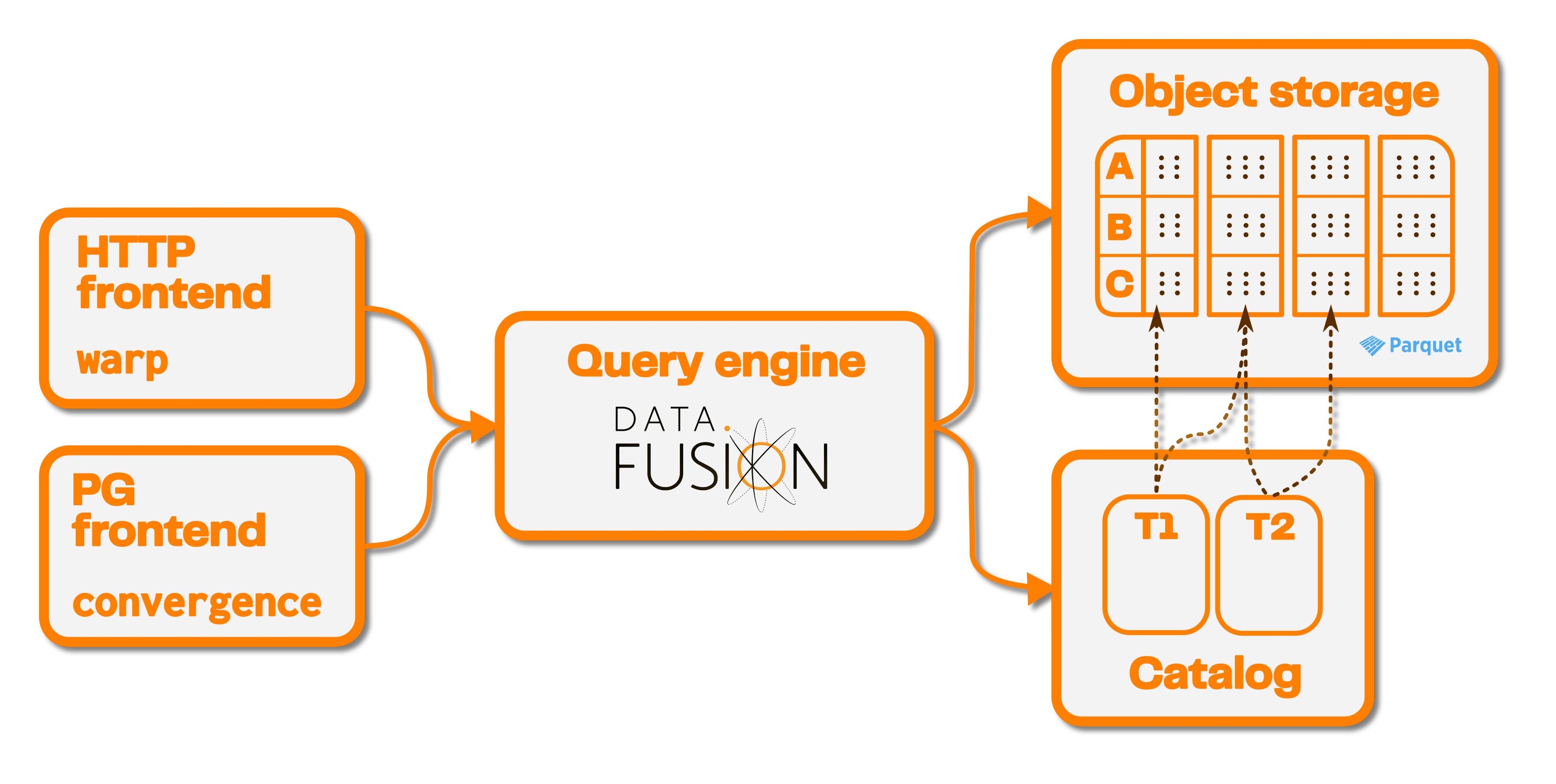
Executor
This component relies heavily on Apache DataFusion for query planning and execution. It runs the actual queries and manages the other components.
Catalog
This is a database that contains Seafowl metadata, such as schema, table and function definitions, relations, etc.
Seafowl supports three catalogs:
- SQLite: default. This has a very low query latency and no external dependencies. However, it means that without tricks like replicating the SQLite database, this limits Seafowl to a single node or a read-only multi-node deployment.
- PostgreSQL: this is higher latency but can be shared between multiple Seafowl instances.
- Memory: an in-memory SQLite database. This is the fastest, but isn't persistent.
Object store
This is where Seafowl stores the actual data as Parquet files.
Seafowl currently supports three object stores:
- Local filesystem: default. This is again most convenient in development and for single-node deployments, but doesn't scale to multiple nodes.
- S3: AWS S3 itself or any other S3-compatible object store. This object store is shared between multiple Seafowl instances, allowing for scaling. However, it is the slowest, as Seafowl will need to download partitions in order to execute queries.
- Memory: store the data in-memory. Fastest, but limited by the node's RAM. Like with the in-memory SQLite catalog, restarting the process loses all data. In addition, combining an in-memory catalog with an persistent object store (or vice versa) will lead to consistency issues.
Seafowl uses the
object_store crate to abstract
away the details of the particular object storage. The crate itself supports
other popular object stores like Azure and GCP, so Seafowl could theoretically
run against those too. We don't officially support this, since:
- it would require shipping the binary with more object-store-specific crates
- we only tested Seafowl on S3
- S3 API has the most open-source (for example, MinIO) and closed-source (for example, Cloudflare R2) implementations
Frontend
This is how you query Seafowl. We only support two:
- HTTP: the main way to upload, write and query data on Seafowl from your application.
- PostgreSQL, provided by the
convergencecrate. This doesn't support authorization or encryption and should only be used in development. We disable it by default.
Default Seafowl configuration
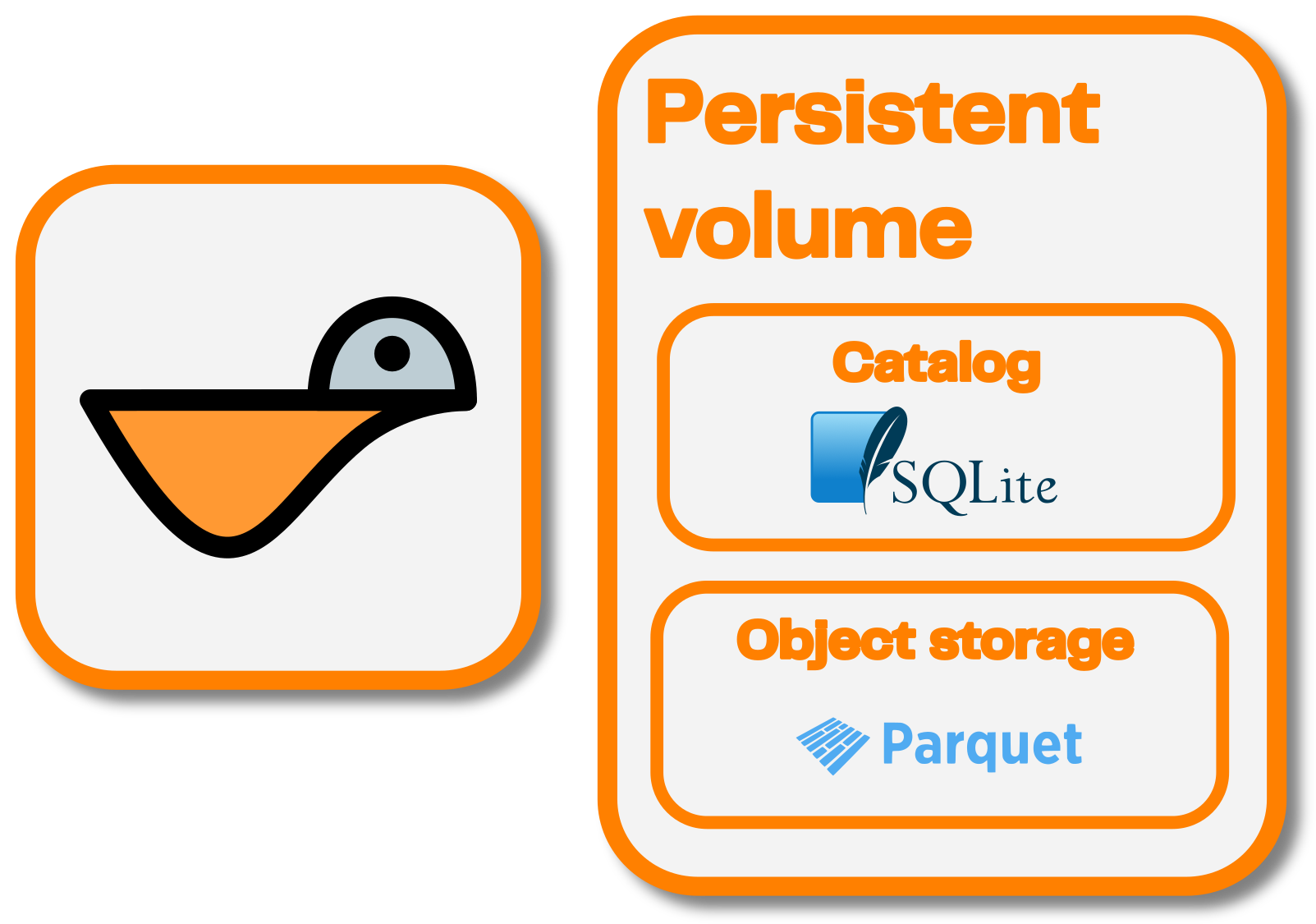
The default configuration for Seafowl is a local filesystem store in
./seafowl-data and a SQLite catalog in ./seafowl-data/seafowl.sqlite. We do
this so that you can easily get started with Seafowl without extra dependencies.

