Scaling to multiple nodes
The default Seafowl installation operates in single-node mode. It uses the local filesystem to store its catalog as a SQLite database and actual data as Parquet files.
While this works well for proofs of concept (and can get you pretty far in production if you cache Seafowl query results), you might find yourself needing to run multiple Seafowl instances to serve more concurrent requests.
This guide will show you how to configure Seafowl to run with a shared PostgreSQL database for the catalog and a shared object storage. This will let you run multiple Seafowl instances, each completely stateless.
Docker Compose example
See our GitHub for an example Docker Compose stack for this deployment pattern.
PostgreSQL as a catalog, Minio as S3 storage
Instead of SQLite, Seafowl also supports a PostgreSQL catalog that is shared
between instances. To configure it, edit the seafowl.toml config file and
replace the default (or use
environment variables):
[catalog]
type = "sqlite"
dsn = "sqlite://./seafowl-data/seafowl.sqlite"
with:
[catalog]
type = "postgresql"
dsn = "postgresql://user:pass@host:port/dbname"
# Custom schema, default "public"
# schema = "public"
To store the actual data, you can use any S3-compatible storage, for example, AWS S3 itself, Cloudflare R2 or a self-hosted MinIO instance.
Change the default:
[object_store]
type = "local"
data_dir = "../seafowl-data"
to (when using AWS S3):
[object_store]
type = "s3"
access_key_id = "AKI..."
secret_access_key = "ABC..."
region = "us-west-2"
bucket = "my-bucket"
Or, if using Minio or localstack, use the endpoint parameter instead of
region:
[object_store]
type = "s3"
access_key_id = "AKI..."
secret_access_key = "ABC..."
endpoint = "http://localhost:9000"
bucket = "my-bucket"
Alternatives
This deployment pattern makes any Seafowl instance support reads and writes. There are alternatives that might be more suitable or efficient for your use case.
Single writer, multiple readers: using SQLite with LiteFS
Instead of using PostgreSQL for the catalog, you can use SQLite with LiteFS.
See our GitHub for an example Docker Compose stack for this deployment pattern.
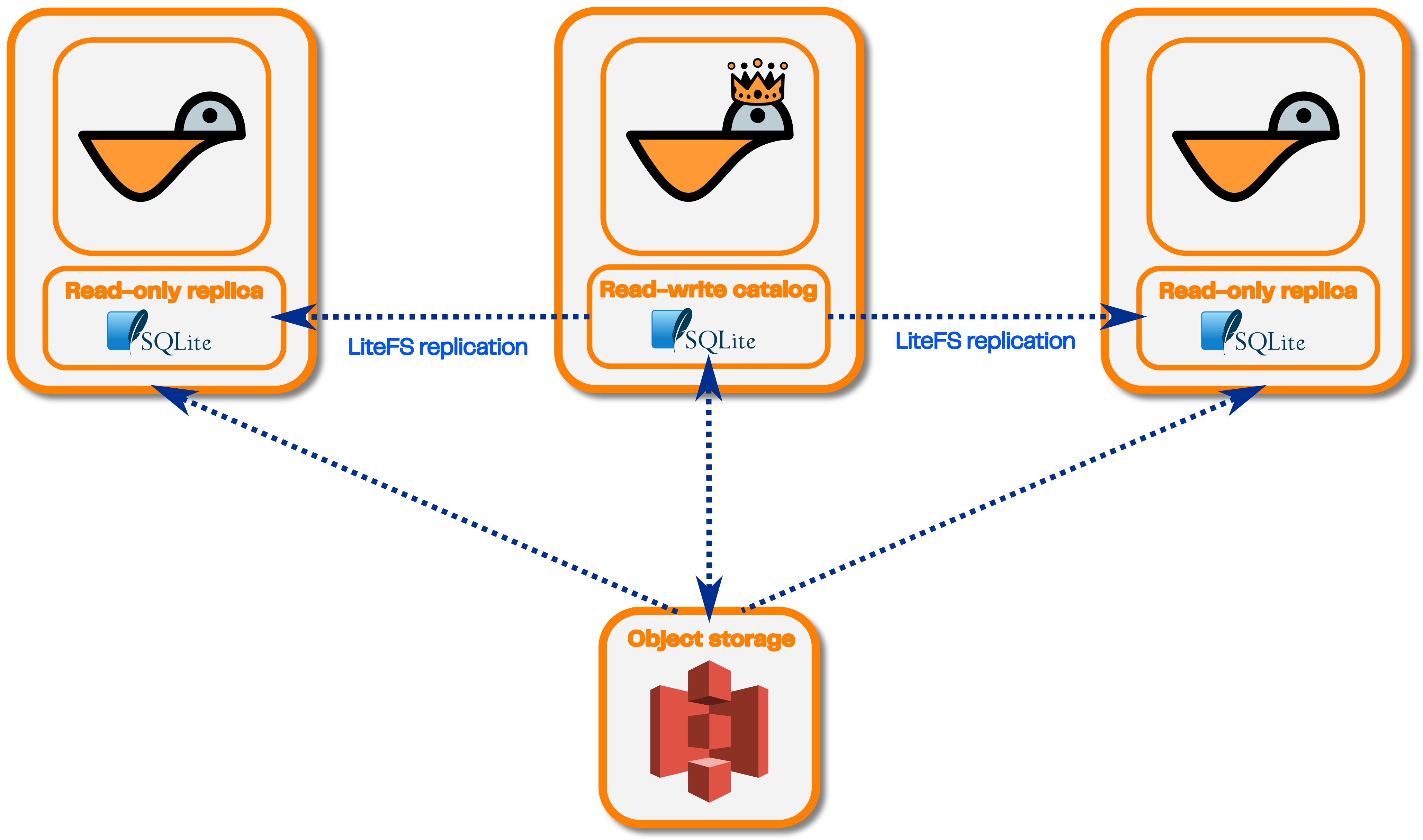
LiteFS is a tool that lets you replicate SQLite databases from a single read-write reader to multiple read-only followers.
This will let you scale Seafowl for low latency read-only queries cheaper in terms of infrastructure costs (since you won't need to deploy a PostgreSQL database or set up PostgreSQL replication). There will be a single Seafowl writer instance that you can send write requests to. Reader Seafowl replicas will pull changes to the SQLite database from the writer and will be otherwise completely stateless.
No writers, many readers: baking the data into a Docker image
If your dataset is small enough (up to a few hundred MB), another possible way to scale Seafowl is to build and deploy a Docker image that contains the Seafowl binary, the SQLite catalog file and the data itself. This has its own tradeoffs. See the relevant section for more details.
Objects can be cached locally
In environments where your Seafowl instance has some scratch disk space, you may wish to use it as object storage cache to speed up queries and reduce traffic to the object store. You can do this by configuring the cache properties section, which provide a couple of control knobs. These include the total size of the disk space allocated for the cached data, TTL for cache eviction and minimum byte range size for fetching (you can also leave the section blank to use the defaults).
Notes
This is not distributed query execution
These deployment patterns only concern the amount of concurrent queries a Seafowl deployment can run. A query that takes 10 seconds with Seafowl will still take 10 seconds if you run multiple Seafowl instances.

