Baking a dataset into a Docker image
For a small enough dataset (which takes less than a few hundred MB in Seafowl), a potential scaling and deployment strategy is building a Docker image that contains the Seafowl binary, the SQLite catalog and the actual Parquet files.
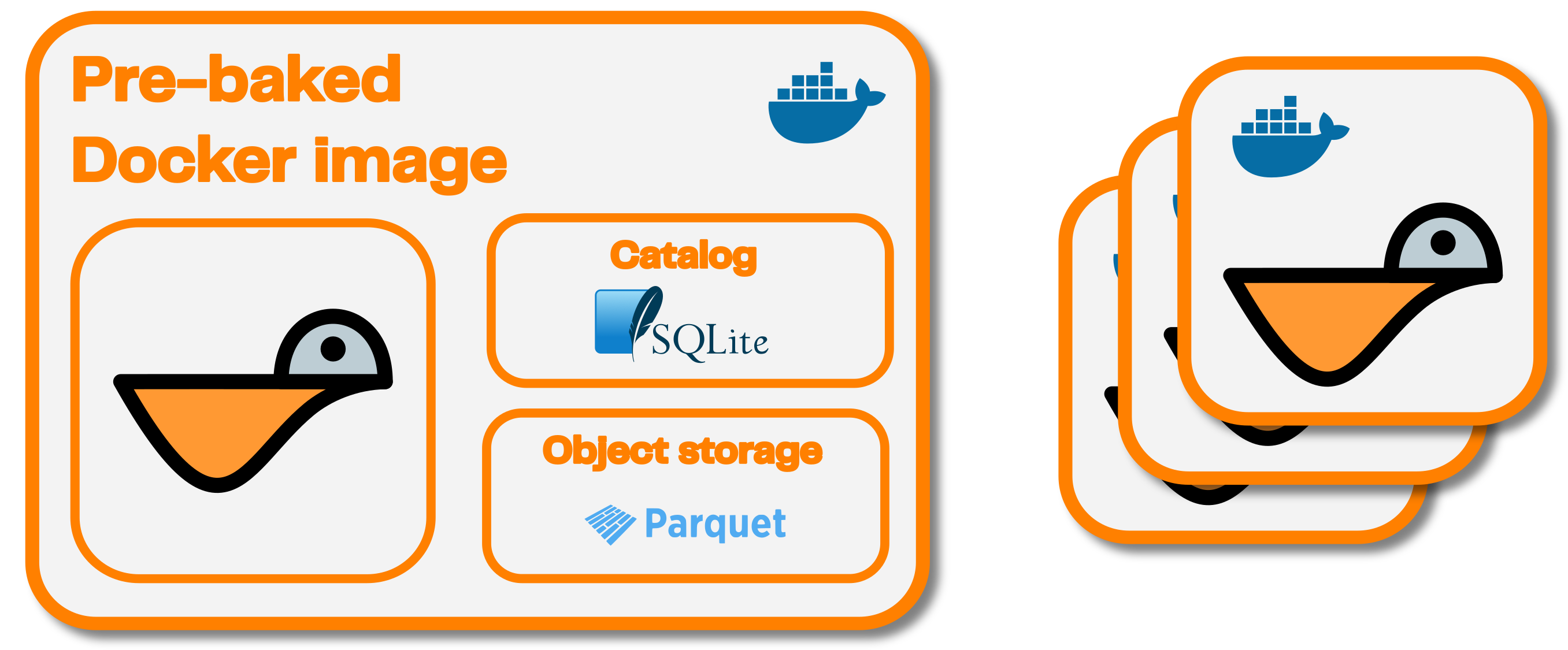
See our GitHub for an example Docker Compose stack for this.
This has some benefits:
- Scaling without any need to set up and run a separate catalog and object store
- Data is co-located with the Seafowl instance, making queries faster
- Can deploy and automatically scale Seafowl to any serverless provider that lets you run a Docker container (e.g. Fly.io or Google Cloud Run).
- Can build and deploy a dataset as part of your CI process
- You can build a self-contained "data product" that is runnable and queryable by any Docker user.
And some drawbacks:
- Doesn't support writes. To update your dataset, you need to redeploy your Seafowl instance.
- Some providers might have a limit on the Docker image size
If these drawbacks are an issue, you might want to take a look at other scaling options.
Running Seafowl with --one-off
When you run Seafowl with --one-off, instead of starting a server, this runs a
single command and exits Seafowl. We'll be using this in the context of a Docker
image.
Building a Docker image
You can use the official Seafowl Docker image that is already configured to run Seafowl:
FROM splitgraph/seafowl:nightly
# Use a single RUN command in which we'll download and delete the source file
# so that it doesn't stay in a Docker layer.
RUN \
curl https://www.cl.cam.ac.uk/research/dtg/weather/weather-raw.csv -o weather-raw.csv && \
seafowl --one-off \
"CREATE EXTERNAL TABLE cambridge_weather (\
timestamp TIMESTAMP,\
temp_c_10 INT NULL,\
humidity_perc INT NULL,\
dew_point_c_10 INT NULL,\
pressure_mbar INT NULL,\
mean_wind_speed_knots_10 INT NULL,\
average_wind_bearing_degrees INT NULL,\
sunshine_hours_100 INT,\
rainfall_mm_1000 INT,\
max_wind_speed_knots_10 INT NULL)\
STORED AS CSV\
LOCATION './weather-raw.csv';\
CREATE TABLE cambridge_weather AS SELECT * FROM staging.cambridge_weather" && \
rm weather-raw.csv
This Dockerfile:
- downloads a CSV file with weather data from https://www.cl.cam.ac.uk/research/dtg/weather/
- creates an external table pointing to this file
- runs
CREATE TABLE AS, storing the CSV file in Seafowl - deletes the source file and the staging table
You can now test this Docker image locally:
DOCKER_BUILDKIT=1 docker build -t seafowl-weather-test .
docker run -d --name seafowl-weather-test-1 -p 127.0.0.1:8080:8080 seafowl-weather-test
curl \
-H "Content-Type: application/json" \
http://localhost:8080/q -d@- <<EOF
{"query": "SELECT date_trunc('month', timestamp) AS month,
AVG(temp_c_10 * 0.1) AS avg_temp
FROM cambridge_weather GROUP BY 1 ORDER BY 2 ASC LIMIT 10"}
EOF
{"month":"2010-12-01 00:00:00","avg_temp":-0.18382749326145384}
{"month":"2018-02-01 00:00:00","avg_temp":1.0846681922196781}
{"month":"2010-01-01 00:00:00","avg_temp":1.3368279569892467}
{"month":"2021-01-01 00:00:00","avg_temp":1.5615591397849464}
{"month":"2017-01-01 00:00:00","avg_temp":1.7540322580645156}
{"month":"2009-01-01 00:00:00","avg_temp":2.276196898179361}
{"month":"2013-03-01 00:00:00","avg_temp":2.369500674763832}
{"month":"2019-01-01 00:00:00","avg_temp":2.500806451612902}
{"month":"1995-12-01 00:00:00","avg_temp":2.592955892034235}
{"month":"2022-01-01 00:00:00","avg_temp":2.6318611987381733}

